目次 - Lesson6
データベース
Lesson 6Chapter 1学習の目標
このレッスンでは、データベースについて学びます。
データベース とは、大量の情報を整理し、一貫性を保ちながら保存・検索・更新するためのソフトウェアです。大量のデジタルデータを扱うアプリケーションや業務には欠かせない存在です。
ここではデータベースとは何か、特徴や基本的な仕組み、設計方法について説明します。また、実際にデータベースの操作を試してみることで理解を深めます。
このレッスンを通して、データベースの仕組みに対する正しいイメージを持ち、ビジネスシーンでのデータ活用をイメージできるようになりましょう。
本レッスンの主な内容
- データベースの基礎
- リレーショナルデータベース
- SQLの基本
- 実際に試してみよう
- データベース設計
本レッスンのゴール
データベースの基礎や設計・運用の考え方、SQLの基本操作を理解し、ビジネスシーンでのデータ活用をイメージできるようになること
本レッスンの前提条件
- ビジネスパーソンに必要なITスキルを把握していること(レッスン1)
- コンピュータの中身について正しいイメージを持っていること(レッスン2)
- ネットワークとインターネットの基本的な仕組み、関連技術、およびそれらがどのようにつながり合っているかを正しく理解していること(レッスン3)
- 情報資産を守るための情報セキュリティの基本概念と3要素、リスク評価、脅威・対策技術、法規制を正しく理解していること(レッスン4)
- アルゴリズムとプログラミングの基礎、システムとプログラムの関係を正しく理解していること(レッスン5)
Lesson 6Chapter 2データベースの基礎
企業では、顧客名簿や受注履歴、在庫リスト、従業員情報など、多種多様なデータを日々取り扱います。
これらを個人のパソコンやExcelファイルで管理していると、関係者が同じ情報を共有できなかったり、更新漏れによって不整合が起こったりする恐れがあります。データベースはこの問題を解決し、組織全体で一元的にデータを活用する土台を提供します。
Lesson 6Chapter 2.1データベースの特徴
データベースは データを永続的に保存 するのに適しています。
データベースは、単にデータを入れておくだけの「箱」ではありません。以下のような、検索や更新などの操作を円滑に行なうための仕組みが組み込まれています。
- 構造化された保存
- データを表形式(リレーショナルデータベースの場合)やキーと値の組(NoSQLの場合)など、あらかじめ定義された形式で格納します。
- これにより、情報をどこに保存しているのか、どの項目を見ればいいのかが明確になります。
- 効率的な検索・更新
- 必要なデータを素早く取り出したり、まとめて更新したりできる仕組みがあります。
- インデックスを設定することで、大量データから目的の情報をすぐに見つけられます。
- 安全な運用
- 権限設定をすることで、閲覧・書き込みが許可されたユーザーだけがデータを操作できます。
- バックアップやリカバリ機能を備えているため、万が一の障害時でもデータを復旧できます。
Lesson 6Chapter 2.2DBMS(データベース管理システム)の役割
DBMS(データベース管理システム:DataBase Management System)は、データベースを作成・管理するためのソフトウェアです。
データベースとDBMSは、よくひとまとめに「データベース」と呼ばれがちですが、本来は次のように区別されます。
- データベース:実際のデータ(テーブルやドキュメントなど)の集合体
- DBMS:データベースを作成・管理するためのソフトウェア
DBMSの機能
DBMSが提供する主な機能は次のとおりです。
- データの格納と取り出し
- SQL(Structured Query Language)などの問い合わせ言語を用いてデータを自由に操作できます。
- ユーザーはSQLを発行するだけで、DBMSがファイル操作やメモリ管理などを自動的に行ないます。
- セキュリティとアクセス制御
- ユーザーのアクセス権限を管理し、データを安全に保護します。
- 誰がどのテーブルを閲覧・更新できるかを設定することで、機密情報への不正アクセスを防ぎます。
- 障害対策とリカバリ
- トランザクション管理とバックアップにより、障害発生時にデータを正しい状態に戻す仕組みを備えています。
- ジャーナルやログファイルを記録することで、障害直前の状態を再現できます。
- データの整合性維持
- テーブル間の整合性や入力規則をDBMSが自動的にチェックします。
- ユニーク制約や外部キー制約を設定しておけば、重複や不整合のあるデータが混在しないようにできます。
DBMSがデータベースを仲介して管理するイメージ
代表的なDBMS製品
代表的なDBMS製品には、以下のようなものがあります。
- PostgreSQL:強力な機能と高い拡張性を備えたオープンソースのリレーショナルデータベース。
- MySQL:オープンソースとして広く利用されるリレーショナルデータベース。
- Oracle Database:エンタープライズ向けの高機能なリレーショナルデータベース製品。
- Microsoft SQL Server:Windows環境との親和性が高く、マイクロソフトの製品群と連携しやすいリレーショナルデータベース。
- SQLite: 組み込み型の軽量なリレーショナルデータベースで、アプリケーションや小規模なプロジェクトに適している。
- Amazon Aurora: クラウド向けに最適化されたリレーショナルデータベースで、MySQLおよびPostgreSQL互換。
- MongoDB: ドキュメント指向のNoSQLデータベースで、JSON形式のデータ構造をサポート。柔軟性が高く、スケーラビリティにも優れている。
- Redis: インメモリ型のNoSQLデータベースで、高速なキャッシュやリアルタイム分析に適している。
Lesson 6Chapter 3リレーショナルデータベース
リレーショナルデータベース(RDB)は、データをテーブル形式で管理するデータベースです。リレーショナルデータベースを管理するシステムを、リレーショナルデータベース管理システム(RDBMS)と呼びます。
リレーショナルデータベースは、データベースのなかで最も広く使われており、多くの業務システムやWebサービスのバックエンドで採用されています。
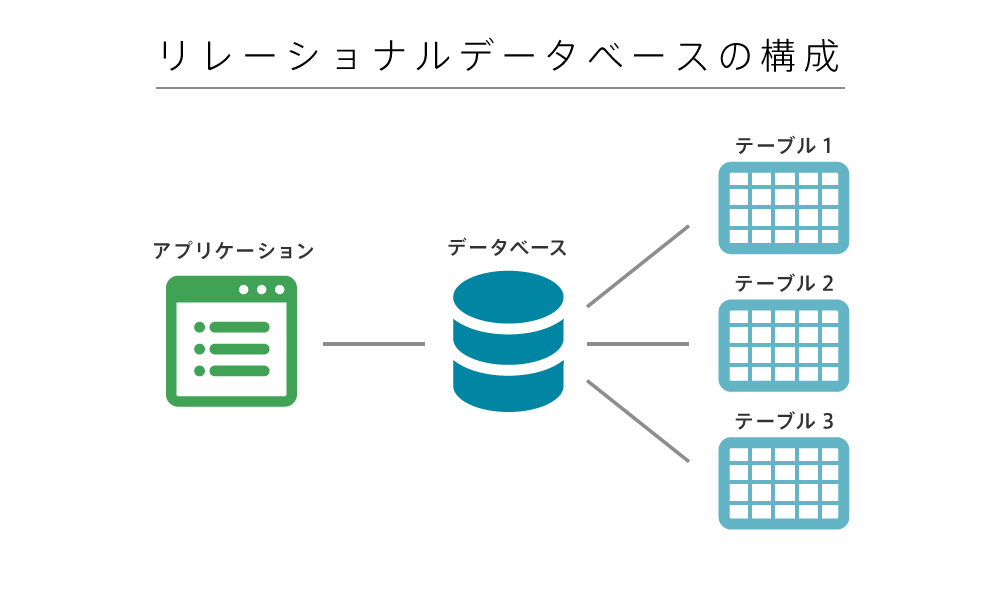
Lesson 6Chapter 3.1リレーショナルデータベースの構成
リレーショナルデータベースの構成は、基本的に1つのアプリケーションに対して1つのデータベースがあり、1つのデータベースの中に複数のテーブル(表)があります。
1つ1つのテーブル(表)は、Excelのシートと同じように縦横の表となっています。
Excelで例えると、Excelファイルが1つのデータベースであり、その中にある複数のシートがテーブル、シートの中の1つ1つのセルが具体的なデータとなるイメージです。
Lesson 6Chapter 3.2リレーショナルデータベースの特徴
リレーショナルデータベースには、以下の特徴があります。
- テーブルは、レコード(行)とカラム(列)で構成される
- カラムには、制約を設定できる
- データの保存や取得などの処理に、SQLという言語を使用する
テーブルは、レコード(行)とカラム(列)で構成される
テーブルは横と縦で構成され、横方向の要素を レコード(行)、縦方向の要素を カラム(列)と呼びます。
レコードは実際のデータの実体、カラムはデータの項目名や属性を示します。
下記のテーブルであれば、ユーザーテーブルのレコードは3件あり、「idカラムの値」が 2 のレコードの、「nameカラムの値」は 次郎 となります。

テーブル内のレコードとカラム
カラムはデータ型を持つ
データ型 は、格納するデータ形式を定義するものです。
下記のテーブルであれば、idには int という整数型が、nameには varchar という文字列型が設定されています。カラムで指定された型以外の値を含んだレコードは保存が失敗するようになっています。

テーブル内のカラムにおけるデータ型
カラムには、制約を設定できる
制約 とは、テーブルのカラム(列)に対して課すルールや制約条件です。
データベースはデータを一元管理しているので、データの整合性や一貫性が求められ、データの不整合がおきてはなりません。制約を設定することによって、カラムの値が不適切にならないよう、データの整合性や品質を保てるようになります。
主な制約には以下があります。
- NOT NULL
- カラムの値が必ず
NULL以外である(空値を許可しない)という制約です。 NULLは、空値(値がない)という意味です。- 例:顧客テーブルの「顧客名」カラムなど、必ず値が入るべきカラムに設定します。
- カラムの値が必ず
- UNIQUE
- カラムの値が「重複してはいけない」という制約です。
- 例:ユーザー名やメールアドレスなど、同じ値が複数存在してはいけない場合に設定します。
- PRIMARY KEY(主キー)
- テーブル内で「一意にレコードを特定」できるようにする制約です。
- 1つのテーブルに設定できる主キーは「1つ」だけです(複数カラムを組み合わせて設定することは可能)。
- FOREIGN KEY(外部キー)
- 他のテーブルの主キーを参照する制約です。
- 外部キー制約があることで、関連するテーブル間のデータ整合性(例:存在しない顧客IDを受注テーブルに記録しない)が保たれます。
- 例:受注テーブルの「顧客ID」が、顧客テーブルの主キーを参照する。
- CHECK
- カラムの値に「特定の条件を満たす」ようにする制約です。
- 例:年齢カラムで「年齢 >= 0」であることを強制する、日付カラムがある期間内へ収まるようにする、など。
- DEFAULT
- カラムに値が指定されなかった場合に「自動的に代入される初期値」を設定する制約です。
- 例:登録日カラムに現在日時の
NOW()をデフォルトで設定する。
データの保存や取得などの処理に、SQLという言語を使用する
リレーショナルデータベースでは、「SQL」というデータベースのための言語を使用して命令文を記述し、データの保存や取得を行ないます。たとえばユーザーテーブル(users)から全員分の名前(name)を取得するには、下記のような命令文となります。
select name from users;
それでは、SQLについて学んでいきましょう。
Lesson 6Chapter 4SQLの基本
SQL(エスキューエル:Structured Query Language)は、主にリレーショナルデータベースを操作するための「問い合わせ言語」です。
SQLには、大きく3つの役割があります。
- データ定義(DDL)
テーブルやインデックスなど、データベースの構造を定義するためのコマンドです。CREATEやALTER、DROPなどが該当します。 - データ操作(DML)
テーブルに対する検索や更新、挿入、削除を行なうためのコマンドです。SELECT、INSERT、UPDATE、DELETEが代表的な例です。 - データ制御(DCL)
ユーザーの権限設定やトランザクション管理に関連するコマンドです。GRANT、REVOKE、COMMIT、ROLLBACKなどがあります。
ここでは主に使用する、データ定義(DDL)とデータ操作(DML)のSQLについて説明します。
Lesson 6Chapter 4.1基本的なデータ定義(DDL)のSQL
ここでは、以下のSQLを紹介します。
- 新しいデータベースを作成する
- データベースを削除したいとき
- テーブルの作成
- テーブルを削除したいとき
新しいデータベースを作成する
データベースの作成は CREATE DATABASE 文を使用します。
書式:
CREATE DATABASE データベース名 [オプション]
オプションは、DBMSによって異なります。たとえば、MySQLでは以下のような指定を行ないます。
CREATE DATABASE データベース名 CHARACTER SET utf8mb4 COLLATE utf8mb4_bin;
CHARACTER SET utf8mb4 COLLATE utf8mb4_binの部分は、データベースで日本語を扱う際に一般的に使用される設定です。
データベースを削除したいとき
データベースの削除は DROP DATABASE 文を使用します。
書式:
DROP DATABASE データベース名;
このSQLは 確認なしでデータベースを即削除 します。そのため、実務では管理者の許可なしにこれを実行することは絶対に避けて ください。どんなに大量のデータがあっても、一瞬で完全に消去されてしまいます。
テーブルの作成
テーブルの作成は CREATE TABLE 文を使用します。
書式:
CREATE TABLE テーブル名 ( 列名 型 オプション, 列名 型 オプション, ... );
テーブルを削除したいとき
テーブルの削除は DROP TABLE 文を使用します。
書式:
DROP TABLE テーブル名;
このSQLは 確認なしでテーブルを即削除 します。そのため、実務では管理者の許可なしにこれを実行することは絶対に避けて ください。どんなに大量のデータがあっても、一瞬で完全に消去されてしまいます。
Lesson 6Chapter 4.2基本的なデータ操作(DML)のSQL
基本的なデータ操作には、次の4つがあります。これらをまとめてCRUD(クラッド)と呼びます。
| 操作 | 日本語 | SQL |
|---|---|---|
| Create | 作成・保存 | INSERT |
| Read | 取得 | SELECT |
| Update | 更新 | UPDATE |
| Delete | 削除 | DELETE |
順番に確認していきましょう。
INSERT文(データの追加)
INSERT は、テーブルに新しい行を挿入するための命令です。基本的な書式は以下のとおりです。
INSERT INTO テーブル名 (列名1, 列名2, ...) VALUES (値1, 値2, ...);
たとえば「顧客テーブル」にデータを追加する際は、以下のように書きます。
INSERT INTO 顧客 (顧客ID, 氏名, 住所, 電話番号) VALUES (1004, '鈴木 次郎', '神奈川県横浜市...', '045-xxxx-xxxx');
テーブルの列定義と挿入するデータの順番や型はそろえる必要があります。挿入が完了すると新しいレコードが追加され、SELECT文で参照できるようになります。
SELECT文(データの抽出)
SELECT は、テーブルから必要なレコードを取り出すための命令です。基本的な書式は以下のとおりです。
SELECT 列名1, 列名2, ... FROM テーブル名 [WHERE 条件];
列名1, 列名2, ...の部分には、取得したい列を指定します。すべて取得する場合は*を使えます。FROM テーブル名で対象のテーブルを指定します。WHERE 条件はオプションです。つけることで、特定の条件を満たす行のみを抽出できます。
たとえば「顧客テーブル」から 氏名 列と 電話番号 列だけを抽出したい場合は次のように書きます。
SELECT 氏名, 電話番号 FROM 顧客;
在住地域が「東京都」の顧客だけを抽出したければ、以下のように WHERE 句を追加します。
SELECT 氏名, 電話番号 FROM 顧客 WHERE 住所 LIKE '東京都%';
UPDATE文(データの更新)
UPDATE は、既存の行の値を変更するための命令です。基本的な書式は以下のとおりです。
UPDATE テーブル名 SET 列名1 = 値1, 列名2 = 値2, ... WHERE 条件;
たとえば「顧客テーブル」で 顧客ID = 1002 の行に対して 住所 列を変更したい場合、以下のようになります。
UPDATE 顧客 SET 住所 = '埼玉県さいたま市〇〇...' WHERE 顧客ID = 1002;
WHERE を指定しないと、すべての行が更新対象となる点に注意が必要です。
DELETE文(データの削除)
DELETE は、テーブルから不要なデータを削除するための命令です。基本的な書式は以下のとおりです。
DELETE FROM テーブル名 WHERE 条件;
たとえば、顧客ID = 1003 の顧客情報を削除したい場合は以下のように書きます。
DELETE FROM 顧客 WHERE 顧客ID = 1003;
これも WHERE をつけないと、テーブル内のすべての行が削除されるため、注意が必要です。特に本番環境で実行するときは、慎重に条件を確認する必要があります。
Lesson 6Chapter 4.3フィルタリング・集計・結合
SQLは単にデータを挿入・更新・削除するだけでなく、複数のテーブルを結合して集計したり、特定の条件に合うレコードだけを取り出したりといった高度な処理を行なえます。ここでは代表的な機能を紹介します。
WHERE句を使ったフィルタリング
前述したように、WHERE 句を使えば指定した条件を満たす行だけを抽出できます。条件式は = や >、< などの演算子や LIKE、BETWEEN、IN などを組み合わせることで、柔軟に設計できます。複数の条件を組み合わせる場合は AND や OR を使って論理演算を行ないます。
SELECT * FROM 顧客 WHERE 住所 LIKE '東京%' AND 登録日 >= '2023-01-01';
上記例では、住所が「東京」で始まり、かつ登録日が2023年1月1日以降の顧客のみを取得します。
GROUP BY句を使ったデータの集計
GROUP BY 句を使うと、テーブルのデータを特定の列でグループ化して集計することができます。たとえば「注文」テーブルにおいて、日付ごとの売上合計金額を集計する場合は、次のようになります。
SELECT 注文日, SUM(金額) AS 日次売上 FROM 注文 GROUP BY 注文日;
ここで SUM のような 集計関数 が利用できます。代表的なものは次のとおりです。
SUM():数値型の合計値を求めるCOUNT():行数を数えるAVG():数値型の平均値を求めるMAX():最大値を求めるMIN():最小値を求める
さらに GROUP BY と HAVING を組み合わせることで、グループ化したあとに追加の条件でフィルタリングをかけることができます。たとえば「売上が一定額を超える日だけ見たい」という場合、集計結果に対して HAVING SUM(金額) > 100000 のような条件を指定できます。
JOINを使ったテーブル結合
複数のテーブルに分散しているデータをまとめて取得するには JOIN が必要です。JOINを使えば、テーブル同士の外部キーなどをもとに、1つの大きな結果セットとして表示できます。以下は JOIN の代表的な種類です。
- INNER JOIN
両方のテーブルに一致する行のみを取得します。 - LEFT JOIN
左側のテーブルの行を優先的にすべて取得し、結合先に該当するものがない場合はNULLが入ります。 - RIGHT JOIN
右側のテーブルの行を優先的にすべて取得します。 - FULL JOIN
両方のテーブルに対して、完全な外部結合を行ないます。どちらか一方のテーブルにしか存在しない行も含めます。
たとえば「顧客」テーブルと「注文」テーブルを連結して、顧客氏名と注文日、注文金額をまとめて取得したい場合は次のように書きます。
SELECT 顧客.氏名, 注文.注文日, 注文.金額 FROM 顧客 INNER JOIN 注文 ON 顧客.顧客ID = 注文.顧客ID;
ここで 顧客ID が両テーブルを結びつける外部キーです。INNER JOIN はあくまで一致する行だけを表示するため、注文がない顧客は結果に出てきません。注文のない顧客も含めたい場合は、LEFT JOIN を使うとよいです。
JOINを活用することで、複雑なデータ分析やレポート作成が容易になります。複数のテーブルから一気に情報を引き出し、集計やソートを行なうなど、柔軟なデータ処理が可能です。
Lesson 6Chapter 5実際に試してみよう
それでは、実際にプログラミングを体験してみましょう。
ここでは、顧客テーブル(customers)を作成し、CRUD(Create, Read, Update, Delete)の一連の操作を行なう流れを示します。
さらに、その次のステップとして、注文テーブル(orders)を作成してテーブル同士の関連性を定義し、フィルタリングやグループ化、JOINによる結合を体験します。
今回も paiza.io を利用します。
- paiza.ioのトップページ にアクセスし「コード作成を試してみる(無料)」のボタンをクリックします。
- エディター画面の左上で「MySQL」を選択すると準備完了です。
paiza.ioを使ううえでの注意点
通常のデータベースは、テーブルの作成やデータを追加した内容は永続化されて保存されますが、paiza.ioは、永続化が行なわれません。
そのため以降のSQLでは、毎回テーブルの作成から行なっていますが、paiza.io特有の書き方としてご認識ください。
Lesson 6Chapter 5.1顧客テーブルの作成
まずは、顧客情報を管理する customers テーブルを作成します。
-- 顧客テーブルの作成 CREATE TABLE customers ( customer_id INT PRIMARY KEY, name VARCHAR(50), address VARCHAR(100), phone VARCHAR(20), registered_date DATE );
--で始まる-- 顧客テーブルの作成はコメントです。customer_idは主キーとして設定し、一意に顧客を特定します。name、address、phone、registered_dateは必要な顧客情報を想定しています。name:顧客名address:住所phone:電話番号registered_date:登録日
- 住所や電話番号は将来的に拡張の可能性があるため、やや大きめのサイズを設定することも検討できます。
- 日付を扱う列には
DATE型を使います。時間まで必要ならDATETIMEを使います。
実行結果:
ここでの出力はありません。
Lesson 6Chapter 5.2CRUD操作
次に、データの登録や更新、削除、検索を行なってみましょう。
ここで示す4つの操作が、RDB(リレーショナルデータベース)で頻繁に利用される基本機能です。
Create(データの追加:INSERT)
テーブルに新規レコードを追加するには、INSERT文を使います。サンプルとして、4件のデータを追加します。
-- 顧客テーブルの作成 CREATE TABLE customers ( customer_id INT PRIMARY KEY, name VARCHAR(50), address VARCHAR(100), phone VARCHAR(20), registered_date DATE ); -- データの追加 INSERT INTO customers VALUES (1001, '田中 太郎', '東京都千代田区〇〇', '03-1234-5678', '2024-01-10'); INSERT INTO customers VALUES (1002, '山田 花子', '神奈川県横浜市〇〇', '045-9876-5432', '2024-01-15'); INSERT INTO customers VALUES (1003, 'John Smith', 'Tokyo, Japan', '090-1111-2222', '2024-01-20'); INSERT INTO customers VALUES (1004, '鈴木 次郎', '埼玉県さいたま市〇〇', '048-5555-6666', '2024-02-01');
実行すると、顧客テーブルに4件のデータが登録されます。INSERT文では、列名と値の順序・データ型を合わせることが基本です。
実行結果:
ここでの出力はありません。
Read(データの読み取り:SELECT)
登録されたデータを確認するには、SELECT文を使います。
-- 顧客テーブルの作成 CREATE TABLE customers ( customer_id INT PRIMARY KEY, name VARCHAR(50), address VARCHAR(100), phone VARCHAR(20), registered_date DATE ); -- データの追加 INSERT INTO customers VALUES (1001, '田中 太郎', '東京都千代田区〇〇', '03-1234-5678', '2024-01-10'); INSERT INTO customers VALUES (1002, '山田 花子', '神奈川県横浜市〇〇', '045-9876-5432', '2024-01-15'); INSERT INTO customers VALUES (1003, 'John Smith', 'Tokyo, Japan', '090-1111-2222', '2024-01-20'); INSERT INTO customers VALUES (1004, '鈴木 次郎', '埼玉県さいたま市〇〇', '048-5555-6666', '2024-02-01'); -- データの読み取り SELECT * FROM customers;
実行結果:
customer_id name address phone registered_date
1001 田中 太郎 東京都千代田区〇〇 03-1234-5678 2024-01-10
1002 山田 花子 神奈川県横浜市〇〇 045-9876-5432 2024-01-15
1003 John Smith Tokyo, Japan 090-1111-2222 2024-01-20
1004 鈴木 次郎 埼玉県さいたま市〇〇 048-5555-6666 2024-02-01
特定の列だけを抽出したい場合
特定の列だけを抽出したい場合は、* の代わりに列名を指定します。また、WHERE句を使えば、条件に合致する行だけを抽出できます。
-- 顧客テーブルの作成 CREATE TABLE customers ( customer_id INT PRIMARY KEY, name VARCHAR(50), address VARCHAR(100), phone VARCHAR(20), registered_date DATE ); -- データの追加 INSERT INTO customers VALUES (1001, '田中 太郎', '東京都千代田区〇〇', '03-1234-5678', '2024-01-10'); INSERT INTO customers VALUES (1002, '山田 花子', '神奈川県横浜市〇〇', '045-9876-5432', '2024-01-15'); INSERT INTO customers VALUES (1003, 'John Smith', 'Tokyo, Japan', '090-1111-2222', '2024-01-20'); INSERT INTO customers VALUES (1004, '鈴木 次郎', '埼玉県さいたま市〇〇', '048-5555-6666', '2024-02-01'); -- 特定の列だけを抽出 SELECT customer_id, name FROM customers WHERE address LIKE '%東京%';
実行結果:
customer_id name
1001 田中 太郎
Update(データの更新:UPDATE)
レコードを修正したい場合は、UPDATE文を使います。たとえば 顧客ID = 1003 の 住所 を変更する例を示します。
-- 顧客テーブルの作成 CREATE TABLE customers ( customer_id INT PRIMARY KEY, name VARCHAR(50), address VARCHAR(100), phone VARCHAR(20), registered_date DATE ); -- データの追加 INSERT INTO customers VALUES (1001, '田中 太郎', '東京都千代田区〇〇', '03-1234-5678', '2024-01-10'); INSERT INTO customers VALUES (1002, '山田 花子', '神奈川県横浜市〇〇', '045-9876-5432', '2024-01-15'); INSERT INTO customers VALUES (1003, 'John Smith', 'Tokyo, Japan', '090-1111-2222', '2024-01-20'); INSERT INTO customers VALUES (1004, '鈴木 次郎', '埼玉県さいたま市〇〇', '048-5555-6666', '2024-02-01'); -- データの更新 UPDATE customers SET address = 'Meguro, Tokyo' WHERE customer_id = 1003; -- 更新されたことを確認 SELECT * FROM customers;
WHERE句を指定しないと、テーブル内の全データが更新されてしまうため注意が必要です。
実行結果:
customer_id name address phone registered_date
1001 田中 太郎 東京都千代田区〇〇 03-1234-5678 2024-01-10
1002 山田 花子 神奈川県横浜市〇〇 045-9876-5432 2024-01-15
1003 John Smith Meguro, Tokyo 090-1111-2222 2024-01-20
1004 鈴木 次郎 埼玉県さいたま市〇〇 048-5555-6666 2024-02-01
Delete(データの削除:DELETE)
不要なデータを削除するには、DELETE文を用います。たとえば、顧客ID = 1004 のデータを削除する場合は次のように書きます。
-- 顧客テーブルの作成 CREATE TABLE customers ( customer_id INT PRIMARY KEY, name VARCHAR(50), address VARCHAR(100), phone VARCHAR(20), registered_date DATE ); -- データの追加 INSERT INTO customers VALUES (1001, '田中 太郎', '東京都千代田区〇〇', '03-1234-5678', '2024-01-10'); INSERT INTO customers VALUES (1002, '山田 花子', '神奈川県横浜市〇〇', '045-9876-5432', '2024-01-15'); INSERT INTO customers VALUES (1003, 'John Smith', 'Tokyo, Japan', '090-1111-2222', '2024-01-20'); INSERT INTO customers VALUES (1004, '鈴木 次郎', '埼玉県さいたま市〇〇', '048-5555-6666', '2024-02-01'); -- データの削除 DELETE FROM customers WHERE customer_id = 1004; -- 削除されたことを確認 SELECT * FROM customers;
これもUPDATEと同様、WHERE句をつけないと全行削除の可能性があるため、実運用では慎重に扱う必要があります。
実行結果:
customer_id name address phone registered_date
1001 田中 太郎 東京都千代田区〇〇 03-1234-5678 2024-01-10
1002 山田 花子 神奈川県横浜市〇〇 045-9876-5432 2024-01-15
1003 John Smith Tokyo, Japan 090-1111-2222 2024-01-20
Lesson 6Chapter 5.3次の操作のための事前準備(注文テーブルの作成)
複数テーブルを扱うために、注文を管理する orders テーブルを作成します。customers テーブルとの関係を示すために、外部キーとして customer_id を設定するのがポイントです。あわせて、このテーブルにいくつかサンプルデータを挿入します。
-- 顧客テーブルの作成 CREATE TABLE customers ( customer_id INT PRIMARY KEY, name VARCHAR(50), address VARCHAR(100), phone VARCHAR(20), registered_date DATE ); -- データの追加 INSERT INTO customers VALUES (1001, '田中 太郎', '東京都千代田区〇〇', '03-1234-5678', '2024-01-10'); INSERT INTO customers VALUES (1002, '山田 花子', '神奈川県横浜市〇〇', '045-9876-5432', '2024-01-15'); INSERT INTO customers VALUES (1003, 'John Smith', 'Tokyo, Japan', '090-1111-2222', '2024-01-20'); INSERT INTO customers VALUES (1004, '鈴木 次郎', '埼玉県さいたま市〇〇', '048-5555-6666', '2024-02-01'); -- 注文テーブルの作成 CREATE TABLE orders ( order_id INT PRIMARY KEY, customer_id INT, order_date DATE, product_name VARCHAR(50), amount INT, CONSTRAINT fk_customer FOREIGN KEY (customer_id) REFERENCES customers (customer_id) ); -- データの追加 INSERT INTO orders (order_id, customer_id, order_date, product_name, amount) VALUES (2001, 1001, '2024-02-10', 'ノートPC', 80000), (2002, 1001, '2024-03-01', 'マウス', 2000), (2003, 1002, '2024-03-15', 'モニター', 20000), (2004, 1003, '2024-03-20', 'キーボード', 5000), (2005, 1003, '2024-03-25', 'プリンター', 20000);
注文テーブルの作成について:
order_idは主キーとして新規の注文を識別します。customer_idはcustomersテーブルのcustomer_idと関連づける外部キーです。order_date、product_name、amountは注文内容を表す列です。- 外部キー制約により、
ordersに存在するcustomer_idは、必ずcustomersテーブルに存在していなければなりません。
データの追加について:
- レコードをまとめて登録する場合は、上記のように
VALUES (...) , (...)とカンマ区切りで連続して指定できます。
実行結果:
ここでの出力はありません。
Lesson 6Chapter 5.4フィルタリング、GROUP BY、JOINを使ったテーブル結合
最後に、少し実践的なSQL操作を試してみます。具体的には、WHERE 句を使った絞り込みや GROUP BY を使った集計、複数テーブルを結合するJOINの操作を確認します。
フィルタリング(WHERE句の活用)
まずは、注文テーブルから、金額が1万円以上の注文のみを抽出する例です。
-- 顧客テーブルの作成 CREATE TABLE customers ( customer_id INT PRIMARY KEY, name VARCHAR(50), address VARCHAR(100), phone VARCHAR(20), registered_date DATE ); -- データの追加 INSERT INTO customers VALUES (1001, '田中 太郎', '東京都千代田区〇〇', '03-1234-5678', '2024-01-10'); INSERT INTO customers VALUES (1002, '山田 花子', '神奈川県横浜市〇〇', '045-9876-5432', '2024-01-15'); INSERT INTO customers VALUES (1003, 'John Smith', 'Tokyo, Japan', '090-1111-2222', '2024-01-20'); INSERT INTO customers VALUES (1004, '鈴木 次郎', '埼玉県さいたま市〇〇', '048-5555-6666', '2024-02-01'); -- 注文テーブルの作成 CREATE TABLE orders ( order_id INT PRIMARY KEY, customer_id INT, order_date DATE, product_name VARCHAR(50), amount INT, CONSTRAINT fk_customer FOREIGN KEY (customer_id) REFERENCES customers (customer_id) ); -- データの追加 INSERT INTO orders (order_id, customer_id, order_date, product_name, amount) VALUES (2001, 1001, '2024-02-10', 'ノートPC', 80000), (2002, 1001, '2024-03-01', 'マウス', 2000), (2003, 1002, '2024-03-15', 'モニター', 20000), (2004, 1003, '2024-03-20', 'キーボード', 5000), (2005, 1003, '2024-03-25', 'プリンター', 20000); -- フィルタリング SELECT * FROM orders WHERE amount >= 10000;
結果として、合計金額が高い注文だけをリストアップできます。必要に応じて日付条件を組み合わせるなどして、柔軟なフィルタリングが可能です。
実行結果:
order_id customer_id order_date product_name amount
2001 1001 2024-02-10 ノートPC 80000
2003 1002 2024-03-15 モニター 20000
2005 1003 2024-03-25 プリンター 20000
GROUP BYを使った集計
GROUP BY 句を使い、顧客ごとの注文合計金額を集計してみます。どの顧客が最も多くの注文をしているかなどの分析に役立ちます。
-- 顧客テーブルの作成 CREATE TABLE customers ( customer_id INT PRIMARY KEY, name VARCHAR(50), address VARCHAR(100), phone VARCHAR(20), registered_date DATE ); -- データの追加 INSERT INTO customers VALUES (1001, '田中 太郎', '東京都千代田区〇〇', '03-1234-5678', '2024-01-10'); INSERT INTO customers VALUES (1002, '山田 花子', '神奈川県横浜市〇〇', '045-9876-5432', '2024-01-15'); INSERT INTO customers VALUES (1003, 'John Smith', 'Tokyo, Japan', '090-1111-2222', '2024-01-20'); INSERT INTO customers VALUES (1004, '鈴木 次郎', '埼玉県さいたま市〇〇', '048-5555-6666', '2024-02-01'); -- 注文テーブルの作成 CREATE TABLE orders ( order_id INT PRIMARY KEY, customer_id INT, order_date DATE, product_name VARCHAR(50), amount INT, CONSTRAINT fk_customer FOREIGN KEY (customer_id) REFERENCES customers (customer_id) ); -- データの追加 INSERT INTO orders (order_id, customer_id, order_date, product_name, amount) VALUES (2001, 1001, '2024-02-10', 'ノートPC', 80000), (2002, 1001, '2024-03-01', 'マウス', 2000), (2003, 1002, '2024-03-15', 'モニター', 20000), (2004, 1003, '2024-03-20', 'キーボード', 5000), (2005, 1003, '2024-03-25', 'プリンター', 20000); -- GROUP BYを使った集計 SELECT customer_id, SUM(amount) AS total_amount FROM orders GROUP BY customer_id;
ここでは SUM() 関数を用いて金額列を合計しています。同様に、COUNT(*) や AVG(amount) など、さまざまな集計を行なうこともできます。
実行結果:
customer_id total_amount
1001 82000
1002 20000
1003 25000
JOINを使ったテーブル結合
最後に、顧客テーブルと注文テーブルを結合して、顧客情報と注文情報を同時に表示する例を示します。両テーブルを関連づける外部キーとして customer_id を使います。
-- 顧客テーブルの作成 CREATE TABLE customers ( customer_id INT PRIMARY KEY, name VARCHAR(50), address VARCHAR(100), phone VARCHAR(20), registered_date DATE ); -- データの追加 INSERT INTO customers VALUES (1001, '田中 太郎', '東京都千代田区〇〇', '03-1234-5678', '2024-01-10'); INSERT INTO customers VALUES (1002, '山田 花子', '神奈川県横浜市〇〇', '045-9876-5432', '2024-01-15'); INSERT INTO customers VALUES (1003, 'John Smith', 'Tokyo, Japan', '090-1111-2222', '2024-01-20'); INSERT INTO customers VALUES (1004, '鈴木 次郎', '埼玉県さいたま市〇〇', '048-5555-6666', '2024-02-01'); -- 注文テーブルの作成 CREATE TABLE orders ( order_id INT PRIMARY KEY, customer_id INT, order_date DATE, product_name VARCHAR(50), amount INT, CONSTRAINT fk_customer FOREIGN KEY (customer_id) REFERENCES customers (customer_id) ); -- データの追加 INSERT INTO orders (order_id, customer_id, order_date, product_name, amount) VALUES (2001, 1001, '2024-02-10', 'ノートPC', 80000), (2002, 1001, '2024-03-01', 'マウス', 2000), (2003, 1002, '2024-03-15', 'モニター', 20000), (2004, 1003, '2024-03-20', 'キーボード', 5000), (2005, 1003, '2024-03-25', 'プリンター', 20000); -- テーブル結合 SELECT c.name AS customer_name, o.order_id, o.product_name, o.amount FROM customers c INNER JOIN orders o ON c.customer_id = o.customer_id;
INNER JOIN は両テーブルに共通して存在するキーのみを表示するため、注文がない顧客は結果に含まれません。注文がない顧客も一覧に表示したい場合は、LEFT JOIN を使えば、顧客テーブルのレコードをすべて含める形にできます。
JOINを使うことで、複数のテーブルを論理的に一体化し、必要な情報を一度に抽出できます。システムが複雑化するほど、テーブル同士の関連付けが増えるため、JOINを活用する頻度も高まります。WHERE句やGROUP BY句と組み合わせれば、よりきめ細かな分析が可能です。
実行結果:
customer_name order_id product_name amount
田中 太郎 2001 ノートPC 80000
田中 太郎 2002 マウス 2000
山田 花子 2003 モニター 20000
John Smith 2004 キーボード 5000
John Smith 2005 プリンター 20000
Lesson 6Chapter 6データベース設計
データベース設計 は、ビジネス要件をもとに、テーブル構造やデータ型、インデックス、トランザクション管理などを決定する工程です。
適切に設計されたデータベースは、効率的な検索と更新を可能にし、障害が発生したときのリカバリも容易にしてくれます。逆に、要件定義が不十分だったり、テーブル定義が複雑すぎたりすると、データの不整合やパフォーマンス低下、保守運用のコスト増大につながる恐れがあります。
こうしたリスクを回避するために、データベース設計のポイントを押さえ、どんなデータをどのように扱うのかを明確にしておく必要があります。
- 要件定義とテーブル設計
- データ型の選定
- インデックスの活用
- トランザクション
Lesson 6Chapter 6.1要件定義とテーブル設計
最初に要件定義でビジネス要件を整理して、データ項目を洗い出します。それをもとに、テーブル構造を設計していきます。
ビジネス要件を整理し、データ項目を洗い出す
関係者にヒアリングなどを行ない、以下のような項目を確認します。
- 取り扱うデータの種類:顧客情報、商品情報、受注・在庫情報、売上実績、問い合わせ履歴など
- データの利用目的:レポート作成、分析、検索、リアルタイム照会など
- 想定するデータ量と更新頻度:1日に何件の登録・更新・削除が発生するか、ピーク時間帯はいつか
- データの保持期間:古いデータも無期限で保存するのか、一定期間でアーカイブするのか
こうした情報を踏まえ、「このテーブルにはどのような列(フィールド)が必要か」「列の型はどれくらいのサイズが妥当か」などの構造を設計します。
適切なテーブル分割による効率的なデータ管理
テーブル設計のポイントは、最適な粒度でテーブルを切り分けることです。
- 1つのテーブルにあまりにも多くの情報を詰め込みすぎると、更新時に無駄な負荷がかかりやすくなるほか、正規化(後述)が不足してデータの重複や不整合が起きやすくなります。
- 逆に細かく分割しすぎると、必要な情報を取得するために多数のテーブルをJOINする必要があるため、パフォーマンスに影響を与える恐れもあります。
- 業務要件やアクセスパターンを分析しながら、最適な粒度でテーブルを切り分けることが重要です。
例:
- 悪い例:顧客情報と注文情報を1つのテーブルにまとめる
- 良い例:「顧客テーブル」と「注文テーブル」に分離し、両者を外部キーで関連づける
テーブル設計と正規化
正規化 とは、リレーショナルデータベースで「データの重複や不整合を減らし、一貫性を高める」テーブル設計手法です。
正規化を行なうと、更新や削除が行ないやすくなり、データが破損するリスクを下げられます。またデータの検索や集計もわかりやすくなり、大規模なシステムであっても運用負荷を抑えられます。
よく使われる正規化の段階としては「第1正規形」「第2正規形」「第3正規形」などがあります。
- 第1正規形:テーブルの各列が「もっとも細かい単位」でデータを保持し、繰り返し要素や配列のような構造を列へ含まないようにします。
- 各列(属性)の値が「単一値」
- 各行が一意に識別される。
- データの列に繰り返しの要素や複数の値が含まれていない。
- 第2正規形:主キーが複数列で構成される場合に、主キーの一部だけに依存する列を分離します。
- 第1正規形を満たしている。
- 主キーの 部分的従属(主キーの一部に依存している属性がある状態)を解消する。
- 第3正規形:主キー以外の列同士の依存関係をなくし、データを完全に主キーにのみ依存させます。
- 第2正規形を満たしている。
- 推移的従属(ある非キー属性が他の非キー属性に依存している状態)を解消する。
リレーション(テーブル間の関係性)
リレーショナルデータベースでは、テーブル間の関係性を明確に定義することで、複数のデータを一貫性をもって扱うことができます。代表的な関係として、以下が挙げられます。
- 一対多(1:N)
1つのレコードが、他のテーブルの複数のレコードと結びつくケースです。たとえば1人の顧客に対して複数の注文が紐づくようなイメージです。 - 多対多(N:M)
1つのレコードが、他のテーブルの複数のレコードと関連し、逆もまた同様であるケースです。たとえば生徒とクラスの関係などが考えられます。多対多を表す場合は、通常「中間テーブル」を用いて、2つの一対多関係に分割します。
Lesson 6Chapter 6.2データ型の選定
データ型の選定も、データベース設計において重要な要素です。
文字列型(VARCHARやCHARなど)の用途
- CHAR(n)
常に指定した長さで保存する固定長の型です。電話番号や郵便番号のように、必ず一定桁数で入力される情報なら扱いやすいです。 - VARCHAR(n)
文字数に応じて可変的に保存する型です。商品名や住所など、桁数が大きく変動する情報ではこちらを選択することが多いです。
数値型(INT、DECIMALなど)の用途
- INT(INTEGER)
整数型です。レコード件数や在庫数量、金額のような小数を含まないデータに適しています。 - DECIMAL(p, s)
固定小数点数型です。金額や注文数量など、小数点以下の精度が必要な数値にはこれを使うことが多いです。 - FLOAT/DOUBLE
浮動小数点数型です。科学技術計算などの用途で用いられますが、金額などでの使用は誤差の影響があるため、注意が必要です。
日付型(DATE、DATETIMEなど)の用途
- DATE
年月日を扱う日付型です。過去や未来の日付まで幅広くサポートされます。 - DATETIME あるいは TIMESTAMP
日付と時刻を合わせて管理したい場合に使います。YYYY-MM-DD HH:MI:SSのように保存され、TIMESTAMPでは製品によって最大範囲が異なるケースもあります。
Lesson 6Chapter 6.3インデックスの活用
インデックス は、テーブルに対して検索を高速化するための仕組みです。
よく使う列にインデックスを張っておけば、検索条件に合致する行を素早く探し出せます。一方で、インデックスが増えるとデータ更新時のオーバーヘッドが大きくなるため、どの列にインデックスを適用すべきかは慎重に決める必要があります。
インデックスの仕組み
多くのデータベースでは、インデックスに「B+木」や「ハッシュ」などのデータ構造を用いています。これにより、テーブルの全行を順番にスキャンするのではなく、インデックスを辿って必要な行だけを直接取得できるようになります。
例:
顧客テーブルの顧客IDにインデックスを張っておく顧客ID = 1003のレコードを探すとき、インデックスを使うと直接その行を見つけられる
もしインデックスがなければ、テーブルの全行に対して「顧客IDが1003かどうか」をチェックする必要があります。レコードが何百万件も存在するような大規模テーブルでは、インデックスを利用しないと検索速度が大幅に低下するおそれがあります。
適切なインデックス設計のポイント
インデックスをむやみに作りすぎると、INSERTやUPDATE、DELETEのたびにインデックス情報を更新しなければならないため、トランザクションの負荷が増えます。以下の点を考慮して、必要最小限のインデックスを設定します。
- 検索頻度の高い列
WHERE句で頻繁に使われる列や、JOINに使われる列にはインデックスを設定する価値があります。 - アップデート頻度とのバランス
データの更新が非常に多い列にインデックスを設定すると、更新コストが増大します。 - ユニーク性
主キーや他のテーブルへの参照に使う外部キーには、インデックスを張っておくことが一般的です。
Lesson 6Chapter 6.4トランザクション
トランザクション とは、データベースにおける一連の処理をまとめた単位のことです。
トランザクションは、すべて成功するか、あるいはすべて失敗して元の状態に戻るかのどちらかにします。
たとえば1件の注文を登録する際、受注情報の追加と在庫数の更新をまとめて1つの「トランザクション」として扱います。トランザクションが途中で失敗した場合は、全体をロールバックし、データを一貫性のある状態に戻します。
ACID特性(原子性、一貫性、隔離性、永続性)
データベースのトランザクション処理には、以下の ACID特性 が求められます。
- 原子性 (Atomicity)
トランザクションがすべての処理を完了するか、まったく行なわれなかった状態に戻すかのどちらかを保証します。 - 一貫性 (Consistency)
トランザクション前後で、データベースのルールや制約が常に有効な状態を保つことを要求します。 - 隔離性 (Isolation)
同時実行される複数のトランザクションがお互い干渉しないようにします。 - 永続性 (Durability)
コミットされたデータは障害が起きても失われず、確実に保存されるようにします。
同時実行制御(排他制御)
同時実行制御 とは、複数のユーザーやアプリケーションが同時にトランザクションを実行しても、整合性を損なわないように制御する仕組みです。
代表的な方法として「ロック機構」があります。ロック機構 は、ある行やテーブルを更新中に、ほかのトランザクションが同じデータを読み書きしようとすると、どちらかを待機またはブロックする仕組みです。DBMSはこの排他制御を自動で行ない、コミットやロールバックのタイミングでロックを解放します。
トランザクション同士が同じリソースを使う場合のイメージ
障害回復
予期せぬ障害によってサーバーがダウンしてしまった場合でも、データベースはログやバックアップを利用して復旧できるように設計されています。
- トランザクションログ
トランザクションの実行履歴を逐次記録し、クラッシュ後に再実行することで整合性を回復します。 - 定期バックアップ
ある時点のデータベースを丸ごと保存しておくことで、障害発生時にそのバックアップから復元できます。
Lesson 6Chapter 7まとめ
このレッスンでは、データベースについて学びました。
リレーショナルデータベースの基本構造やSQLによるCRUD操作を体験することで、データを一元管理し、効率的に検索・更新・集計できる仕組みを理解しました。
また、テーブル間の関連づけや正規化、インデックスの活用を通して、データの重複や不整合を防ぎつつ高速アクセスを可能にする設計手法の重要性を確認しました。
データベースは、企業の業務システムやIT活用に必要不可欠です。ビジネスパーソンの業務知識を生かし、組織内でのデータ活用やデータ分析が行なえるようになりましょう。
このレッスンで学んだこと
このレッスンで学んだことを振り返り、理解度を確認しましょう。
- データベースは、大量の情報を一元的に管理し、組織全体で整合性を保ちながら利用するための仕組み。個人管理やファイルベース管理の弱点(更新漏れ・不整合など)を解消し、効率的なデータ活用を可能にする。
- DBMS(DataBase Management System)は、データベースを作成・管理するソフトウェア。ユーザーはSQLなどの問い合わせ言語を使うだけで、実際のファイル操作やメモリ管理はDBMSが自動的に処理する。
- リレーショナルデータベースでは、データをテーブル(行=レコード、列=カラム)形式で管理し、外部キーを使ってテーブル同士を関連づける。システムの多くはRDBMSを採用し、表形式で扱うデータを構造的に保管できる。
- SQLは、テーブルの作成・変更(DDL)、データの検索・追加・更新・削除(DML)、アクセス権限やトランザクション管理(DCL)などを行なうための問い合わせ言語。
- CRUD(Create・Read・Update・Delete)は、テーブル操作の基本セット。INSERTによるデータ追加、SELECTによる検索、UPDATEによる更新、DELETEによる削除。
- WHERE句を使ったフィルタリング、GROUP BY句を使った集計、JOIN(INNER JOIN/LEFT JOINなど)によるテーブル結合を活用し、複数テーブルのデータをまとめて分析したり、柔軟なレポートを作成したりできる。
- データベース設計では、正規化によるデータの重複や不整合の防止が重要。第1正規形~第3正規形の考え方を活かしてテーブルを最適に分割することで、更新や検索を効率化し、運用コストを下げられる。
- インデックスを適切に設定すると、大量データからの検索速度が大幅に向上する。ただし、インデックスが多すぎると更新系処理の負荷が増えるため、アクセス頻度や更新頻度とのバランスを考慮する必要がある。
- トランザクションとACID特性(原子性・一貫性・隔離性・永続性)によって、安全かつ整合性を保ったデータ処理が可能。障害時のロールバックや同時実行制御の仕組みを理解しておくと、業務システムの設計や運用で役立つ。
課題データベースの理解度確認
下記の5つの質問に答えてください。「回答フォーマット」をコピーして、コメント欄に記入して提出してください。
- リレーショナルデータベースのテーブルは、どのような構造でデータを管理していますか?
- CRUDとは何を指し、SQLではどの命令で操作しますか?
- テーブルに設定できる制約(NOT NULL、PRIMARY KEY、FOREIGN KEYなど)は何を制御するための仕組みですか?
- データベース設計でいう正規化とはどのような目的があり、どのような利点がありますか?
- ACID特性(原子性、一貫性、隔離性、永続性)は何を保証するための概念ですか?「トランザクション」を使って回答してください。
回答フォーマット
1.
2.
3.
4.
5.